Đăng ký nhận báo giá
Học máy (Machine Learning) là gì? Khái niệm, ứng dụng và cách thức hoạt động


Học máy (Machine Learning) không còn là thuật ngữ xa lạ.
Từ các trợ lý ảo thông minh như Siri, Google Assistant đến các hệ thống đề xuất nội dung trên Netflix, TikTok, tất cả đều đang vận hành dựa trên nền tảng của Machine Learning để phân tích dữ liệu, học hỏi hành vi và đưa ra dự đoán chính xác.
Và nếu bạn từng mở khóa điện thoại bằng nhận diện khuôn mặt hoặc tương tác với trợ lý ảo, bạn đã trực tiếp trải nghiệm "machine learning".
Nhưng bản chất thật sự của máy học (machine learning) là gì?
Vì sao lại có tầm ảnh hưởng sâu rộng đến thế giới hiện đại?
Bài viết được xây dựng nhằm mục đích giải thích cụ thể học máy (machine learning) là gì, cung cấp những thông tin toàn diện cho quý độc giả về ứng dụng, cách thức hoạt động và ứng dụng trong nhiều lĩnh vực khác nhau.
Học máy (machine learning) là gì?
Học máy (machine learning) là một lĩnh vực thuộc trí tuệ nhân tạo (AI) tập trung vào việc nghiên cứu và phát triển các thuật toán máy tính có khả năng tự động cải thiện để giải quyết các vấn đề thông qua dữ liệu và trải nghiệm thực tế.
Thuật ngữ "machine learning" lần đầu được làm rõ vào nằm 1959 bởi nhà khoa học máy tính Arthur Samuel, người đã định nghĩa "học máy" là "khả năng học của máy tính mà không cần được lập trình rõ ràng". Đơn giản hơn, học máy cho phép các hệ thống tự học và cải thiện bằng cách sử dụng deep learning và mạng nơ-ron, mà không cần được lập trình rõ ràng cho mỗi nhiệm vụ, bằng cách cung cấp cho hệ thống một lượng lớn dữ liệu. Các thuật toán cũng thích nghi với dữ liệu và thông tin mới để cải thiện theo thời gian.
Về bản chất, machine learning giúp hệ thống có khả năng nhận diện quy luật từ dữ liệu, thực hiện dự đoán hoặc phân loại và tự động tối ưu hoá hiệu suất dựa trên kinh nghiệm. Cho phép máy tính và máy móc học hỏi từ dữ liệu và cải thiện hiệu suất cũng như độ chính xác. Từ đó giải quyết các bài toán mà không cần con người phải can thiệp quá nhiều.

Mô tả cách thuật toán hoạt động trong một chu kỳ
Đại học California Berkeley chia hệ thống học tập của thuật toán học máy thành ba phần chính:
Quy trình quyết định: Thuật toán học máy được sử dụng để đưa ra dự đoán hoặc phân loại. Dựa trên một số dữ liệu đầu vào, có thể được gắn nhãn hoặc không gắn nhãn, thuật toán của bạn sẽ đưa ra ước tính về một mẫu trong dữ liệu.
Hàm lỗi: Hàm lỗi đánh giá dự đoán của mô hình. Khi thuật toán đưa ra dự đoán, cần có một cơ chế đánh giá để xác định mức độ chính xác của kết quả. Hàm lỗi đóng vai trò như một thước đo, phản ánh sự khác biệt giữa giá trị dự đoán và giá trị thực tế.
Ví dụ, trong bài toán phân loại, có thể sử dụng hàm entropy chéo (Cross-Entropy Loss) để đo lường độ sai lệch giữa phân bố dự đoán và nhãn thực tế.
Quá trình tối ưu hóa mô hình: Sau khi tính toán hàm lỗi, thuật toán sẽ điều chỉnh các tham số của mô hình để giảm sai số và cải thiện hiệu suất dự đoán. Quá trình này thường sử dụng:
- Gradient Descent: Một phương pháp tối ưu hóa phổ biến giúp điều chỉnh trọng số của mô hình bằng cách giảm thiểu giá trị hàm lỗi.
- Backpropagation: Được sử dụng trong các mạng nơ-ron nhân tạo (Neural Networks), giúp cập nhật trọng số qua nhiều lớp ẩn để tối ưu hóa đầu ra.
- Regularization: Kỹ thuật giúp ngăn mô hình bị overfitting (quá khớp với dữ liệu huấn luyện) bằng cách thêm một số ràng buộc vào quá trình học.
Ví dụ: nếu bạn đang xây dựng một hệ thống đề xuất phim, bạn có thể cung cấp thông tin về bản thân và lịch sử xem của mình dưới dạng đầu vào. Thuật toán sẽ nhận đầu vào đó và học cách trả về đầu ra chính xác: những bộ phim bạn sẽ thích. Một số đầu vào có thể là những bộ phim bạn đã xem và được đánh giá cao, tỷ lệ phần trăm các bộ phim bạn đã xem là phim hài hoặc có bao nhiêu bộ phim có một diễn viên cụ thể. Công việc của thuật toán là tìm các tham số này và gán trọng số cho chúng. Nếu thuật toán làm đúng, trọng số mà nó sử dụng vẫn giữ nguyên. Nếu nó làm sai một bộ phim, trọng lượng dẫn đến quyết định sai sẽ bị từ chối để nó không mắc phải loại sai lầm đó một lần nữa (Theo: Berkeley).
Đây được xem là cách tiếp cận tổng quát, nhấn mạnh các thành phần cốt lõi, giúp các bạn hiểu nhanh về machine learning. Ở phần tiếp theo trong bài, VR360 sẽ đề cập sâu hơn vào cách thức hoạt động chi tiết.
Tại sao học máy lại quan trọng?
"Machine Learning là điện năng mới của thế giới."
Andrew Ng - Nhà khoa học AI hàng đầu, cựu Giám đốc AI tại Baidu, đồng sáng lập Coursera)
Học máy đóng vai trò ngày càng quan trọng trong xã hội loài người kể từ khi bắt đầu vào giữa thế kỷ 20, khi những người tiên phong về AI như Walter Pitts, Warren McCulloch, Alan Turing và John von Neumann đặt nền tảng tính toán cho lĩnh vực này.
Xã hội hiện đại đang tạo ra một lượng dữ liệu khổng lồ mỗi ngày.
Từ hoạt động trực tuyến, giao dịch tài chính đến dữ liệu y tế và cảm biến IoT... tất cả đều cần được phân tích để rút ra những thông tin giá trị.
Tuy nhiên, khả năng xử lý dữ liệu của con người có giới hạn và đây chính là lúc học máy phát huy vai trò.
Việc đào tạo máy móc để học hỏi từ dữ liệu và cải thiện theo thời gian đã cho phép các tổ chức tự động hóa các tác vụ thường lệ. Về mặt lý thuyết, điều này giải phóng con người để theo đuổi công việc sáng tạo và chiến lược hơn.
Học máy không chỉ giúp tự động hóa các tác vụ lặp đi lặp lại, mà còn có khả năng phát hiện các mẫu dữ liệu phức tạp và đưa ra quyết định tối ưu. Điều này mang lại lợi ích to lớn trong nhiều lĩnh vực:
- Trong tài chính, học máy có chức năng phát hiện gian lận và quản lý rủi ro: Các ngân hàng và tổ chức tài chính ngày nay dựa vào Machine Learning để giám sát hàng triệu giao dịch trong thời gian thực nhằm phát hiện hoạt động gian lận.
Các mô hình học máy có thể...
Nhận diện các giao dịch bất thường dựa trên hành vi tiêu dùng của khách hàng.
Dự đoán rủi ro tín dụng, giúp các ngân hàng đánh giá chính xác khả năng thanh toán của người vay.
Tối ưu hóa danh mục đầu tư bằng cách phân tích xu hướng thị trường và dự báo biến động.
Nhờ tốc độ xử lý nhanh và độ chính xác cao, Machine Learning giúp ngành tài chính giảm thiểu tổn thất và tăng cường an ninh giao dịch.
Trong chăm sóc sức khỏe, học máy hỗ trợ bác sĩ chẩn đoán bệnh dựa trên hình ảnh y tế và thông báo kế hoạch điều trị bằng các mô hình dự đoán kết quả của bệnh nhân.
Machine Learning đang thay đổi cách các bác sĩ và chuyên gia y tế đưa ra quyết định lâm sàng.
Các hệ thống AI như IBM Watson Health có thể quét hàng triệu nghiên cứu y khoa để đề xuất phương án điều trị tối ưu trong thời gian ngắn, điều mà một bác sĩ khó có thể làm được thủ công.
Trong bán lẻ, các công ty thương mại điện tử và bán lẻ đang sử dụng ML để cá nhân hóa trải nghiệm mua sắm, dự đoán nhu cầu hàng tồn kho và tối ưu hóa chuỗi cung ứng. Các nền tảng như Amazon, Shopee, Lazada sử dụng ML để đề xuất sản phẩm phù hợp dựa trên sở thích và lịch sử mua sắm của người dùng.
Machine Learing cũng thực hiện các tác vụ thủ công vượt quá khả năng thực hiện của con người ở quy mô lớn.
Ví dụ xử lý lượng dữ liệu khổng lồ được tạo ra hàng ngày bởi các thiết bị kỹ thuật số. Khả năng trích xuất các mẫu và thông tin chi tiết từ các tập dữ liệu khổng lồ này đã trở thành một yếu tố tạo nên sự khác biệt cạnh tranh trong các lĩnh vực như ngân hàng và khám phá khoa học.
Nhiều công ty hàng đầu hiện nay, bao gồm Meta, Google và Uber, tích hợp ML vào hoạt động của họ để đưa ra quyết định và cải thiện hiệu quả.
Có những loại học máy nào?
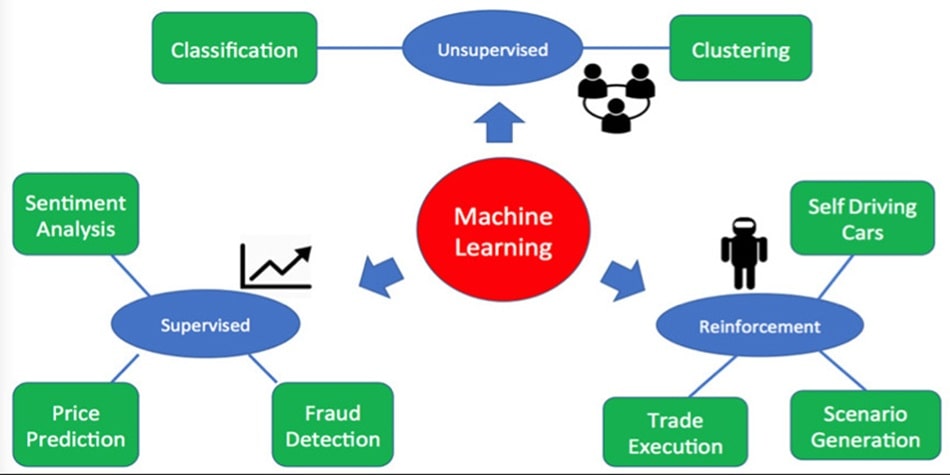
Machine Learning cổ điển thường được phân thành 4 loại cơ bản:
Supervised Learning
Là phương pháp phổ biến nhất trong ML, trong đó thuật toán được huấn luyện bằng một tập dữ liệu có nhãn (tức là dữ liệu đã biết đầu vào và đầu ra mong muốn). Mục tiêu là học được mối quan hệ giữa đầu vào và đầu ra để có thể dự đoán chính xác khi gặp dữ liệu mới.
Ví dụ: Trong nhận dạng chữ viết tay, với ảnh của hàng nghìn mẫu chữ số được viết bởi nhiều người khác nhau. Đào tạo để có thể nhận diện mỗi bức ảnh tương ứng với từng chữ số. Sau khi thuật toán tạo ra một mô hình, tức một hàm số mà đầu vào là một bức ảnh và đầu ra là một chữ số. Được ứng dụng trong chuyển đổi chữ viết tay thành văn bản số, nhận dạng chữ số trên biển số xe.
Unsupervised Learning
Không giống như Supervised Learning, Unsupervised Learning không có nhãn dữ liệu. Thay vào đó, thuật toán cố gắng tìm ra cấu trúc hoặc mẫu trong dữ liệu bằng cách nhóm các điểm dữ liệu có tính chất tương tự lại với nhau.
Ví dụ như phân nhóm hoặc giảm số chiều của dữ liệu để thuận tiện trong việc lưu trữ và tính toán.
Unsupervised Learning có hiệu quả đối với nhiều nhiệm vụ khác nhau như: Chia tập dữ liệu thành các nhóm dựa trên mức độ tương đồng, xác định các điểm dữ liệu bất thường trong một tập dữ liệu bằng thuật toán phát hiện bất thường.
Semi-Supervised Learning
Mô hình được huấn luyện với một lượng nhỏ dữ liệu có nhãn và một lượng lớn dữ liệu chưa có nhãn, giúp tận dụng dữ liệu chưa có nhãn để cải thiện độ chính xác của mô hình.
Từ dữ liệu này, thuật toán học các chiều của tập dữ liệu, sau đó có thể áp dụng cho dữ liệu mới, chưa được gắn nhãn. Tuy nhiên, lưu ý rằng việc cung cấp quá ít dữ liệu đào tạo có thể dẫn đến quá khớp, trong đó mô hình chỉ ghi nhớ dữ liệu đào tạo thay vì thực sự học các mẫu cơ bản.
Giả sử bạn muốn dạy máy tính phân loại hình ảnh chó và mèo. Bạn có một số ít ảnh đã được gán nhãn (chẳng hạn 1.000 ảnh chó/mèo do con người dán nhãn) và một lượng lớn ảnh chưa có nhãn thu thập từ internet (hàng chục nghìn ảnh khác).
Đầu tiên, máy học sẽ học từ dữ liệu có nhãn để phân biệt chó và mèo. Sau đó, sử dụng những gì đã học để tự gán nhãn và huấn luyện trên dữ liệu chưa có nhãn. Loại này giúp mô hình đạt hiệu suất cao mà không cần tốn quá nhiều công sức dán nhãn dữ liệu.
Reinforcement Learning
Một chương trình máy tính không sử dụng dữ liệu có sẵn mà hoạt động bằng cách tương tác với môi trường và học hỏi từ phản hồi. Đây là phương pháp phổ biến trong các hệ thống yêu cầu tự động ra quyết định tối ưu theo thời gian thực.
Reinforcement Learning thường được sử dụng cho các nhiệm vụ như sau: Giúp robot học cách thực hiện các nhiệm vụ trong thế giới vật lý, dạy bot chơi trò chơi điện tử và thậm chí là giúp doanh nghiệp lập kế hoạch phân bổ nguồn lực.
Việc lựa chọn thuật toán phụ thuộc vào bản chất của dữ liệu. Nhiều thuật toán và kỹ thuật không giới hạn ở một loại Machine Learning duy nhất; có thể được điều chỉnh cho nhiều loại tùy thuộc vào vấn đề và tập dữ liệu.
Ví dụ, các thuật toán học sâu như mạng nơ-ron tích chập và mạng nơ-ron hồi quy được sử dụng trong các tác vụ Supervised Learning, Unsupervised Learning và Reinforcement Learning, dựa trên vấn đề cụ thể và tính khả dụng của dữ liệu.
Cách hoạt động của học máy
Ở phần này, mục tiêu của VR360 là giúp bạn có các nhìn tổng quan về cách hoạt động của học máy. Chúng tôi cũng sẽ không đi quá sâu vào việc phân tích các khía cạnh chuyên môn.
Về cốt lõi, học máy sử dụng các thuật toán, bạn cũng có thể hiểu là danh sách các quy tắc, đã được điều chỉnh dựa trên các dữ liệu trong quá khứ để đưa ra phân tích, dự đoán cho các dữ liệu mới. Ví dụ: một thuận toán học máy được "đào tạo" dựa trên tệp dữ liệu bao gồm hàng ngàn hình ảnh về các loài hoa, được gắn nhãn thông tin dựa trên tên của các loại hoa. Từ đó, hệ thống có thể xác định chính xác một bông hoa trong một bức ảnh mới dựa trên các đặc điểm riêng biệt mà thuật toán đã học được từ các bức ảnh khác.
Để đảm bảo các thuật toán hoạt động hiệu quả, chúng thường được tinh chỉnh nhiều lần cho đến khi tích lũy đầy đủ dữ liệu để hoạt động chính xác. Trong vài trường hợp, nhiều thuật toán sẽ được kết hợp với nhau để tạo ra các mạng lưới phức tạp cho phép chúng giải quyết các vấn đề lớn hơn, phức tạp hơn.
Kết quả là dù các nguyên tắc cơ bản tương đối đơn giản nhưng các mô hình được tạo ra vào cuối quá trình có thể trở nên rất phức tạp. Để hiểu hơn về quá trình chuyển đổi dữ liệu thô thành thông tin có giá trị, cùng VR360 đi sâu vào quy trình 7 bước
Bước 1: Thu thập dữ liệu
Bước đầu tiên là thu thập dữ liệu từ nhiều nguồn khác nhau, có thể từ tệp cơ sở dữ liệu, tệp văn bản, hình ảnh, tệp âm thanh hoặc thậm chí được thu thập từ website.
Bước 2: Tiền xử lý dữ liệu
Đây là bước quan trọng trong quá trình học máy, bao gồm việc loại bỏ các dữ liệu trùng lặp, sửa lỗi, xử lý các dữ liệu còn thiếu và chuẩn hóa dữ liệu, đưa về định dạng tiêu chuẩn.
Quá trình này giúp nâng cao chất lượng dữ liệu và đảm bảo mô hình học máy có thể diễn giải chính xác thông tin. Bước này có thể cải thiện đáng kể độ chính xác của mô hình.
Bước 3: Chọn mô hình phù hợp
Sau khi dữ liệu được chuẩn bị, bước tiếp theo là chọn mô hình máy học. Việc lựa chọn mô hình phụ thuộc vào bản chất dữ liệu của bạn và vấn đề bạn đang cố gắng giải quyết. Các yếu tố cần xem xét khi chọn mô hình bao gồm kích thước và loại dữ liệu, độ phức tạp của vấn đề và tài nguyên tính toán có sẵn.
Bước 4: Đào tạo mô hình
Quá trình huấn luyện bao gồm việc đưa dữ liệu vào mô hình và cho phép điều chỉnh các tham số nội bộ để dự đoán kết quả tốt hơn. Trong quá trình này, cần tránh hiện tượng overfitting (mô hình hoạt động tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu mới) và underfitting (mô hình hoạt động kém trên cả dữ liệu huấn luyện và dữ liệu mới).
Bước 5: Đánh giá mô hình
Khi một mô hình được huấn luyện, việc đánh giá hiệu suất là vô cùng quan trọng. Với MLOps, việc giám sát không dừng lại ở giai đoạn ban đầu mà bao gồm đánh giá liên tục để phát hiện hiện tượng model drift (khi hiệu suất giảm do thay đổi trong mẫu dữ liệu) và duy trì chất lượng mô hình theo thời gian. Các quy trình giám sát và huấn luyện lại liên tục giúp các tổ chức đảm bảo mô hình vẫn hiệu quả.
Các chỉ số phổ biến để đánh giá hiệu suất mô hình bao gồm độ chính xác, độ bao quát, cùng sai số trung bình.
Bước 6: Tối ưu hóa
Nhiều đội ngũ sử dụng các nền tảng MLOps (Machine Learning Operations) hỗ trợ, giúp các thí nghiệm có thể lặp lại và được ghi chép đầy đủ, cho phép tối ưu hóa nhất quán theo thời gian.
Các kỹ thuật điều chỉnh siêu tham số bao gồm tìm kiếm dạng lưới (grid search - thử các tổ hợp tham số khác nhau) và xác thực chéo (cross validation - chia dữ liệu thành các tập con và huấn luyện mô hình trên từng tập để đảm bảo hiệu suất trên dữ liệu khác nhau).
Bước 7: Dự đoán và triển khai
Triển khai một mô hình học máy bao gồm việc tích hợp nó vào môi trường thực tế nơi nó có thể cung cấp dự đoán hoặc thông tin theo thời gian thực. MLOps đã giúp đơn giản hóa quy trình này. Nó bao gồm kiểm soát, giám sát và kiểm thử tự động để đảm bảo mô hình có thể tái lập, đáng tin cậy và mạnh mẽ. Các khung MLOps như MLflow hoặc Kubeflow hỗ trợ các mục tiêu này bằng cách cung cấp quy trình triển khai, huấn luyện lại và quay lại mô hình khi gặp vấn đề.
Ứng dụng Machine Learning cho doanh nghiệp
Học máy đã trở thành một phần không thể thiếu của phần mềm kinh doanh. Sau đây là một số ví dụ về cách các ứng dụng kinh doanh khác nhau sử dụng ML:
Trí tuệ kinh doanh (Business Intelligence – BI): Phần mềm phân tích dự đoán và BI sử dụng các thuật toán ML, bao gồm hồi quy tuyến tính và hồi quy logistic, để xác định các điểm dữ liệu, mô hình và phát hiện bất thường trong các tập dữ liệu lớn.
Những hiểu biết sâu sắc này giúp doanh nghiệp đưa ra quyết định dựa trên dữ liệu, dự báo xu hướng và tối ưu hóa hiệu suất. Những tiến bộ trong AI tạo sinh cũng cho phép tạo ra các báo cáo và bảng thông tin chi tiết tóm tắt dữ liệu phức tạp theo các định dạng dễ hiểu.
Quản lý quan hệ khách hàng: Các ứng dụng ML chính trong CRM bao gồm phân tích dữ liệu khách hàng để phân khúc khách hàng, dự đoán hành vi, đưa ra các đề xuất được cá nhân hóa, điều chỉnh giá, tối ưu hóa các chiến dịch email, cung cấp hỗ trợ chatbot và phát hiện gian lận. Hiện tại, các chatbot được VR360 tích hợp trong các dự án VRTour cũng đang được ứng dụng công nghệ này.
Bảo mật và tuân thủ: Machine Learning giúp tăng cường bảo mật bằng cách phát hiện các mỗi đe doạ tiềm ẩn. Máy vectơ hỗ trợ có thể phân tích các sai lệch bất thường, từ đó xác định nguy cơ tấn công mạng. Trong khi đó, mạng đối kháng tạo sinh có thể tạo ra mẫu phần mềm độc hại giả lập, giúp các hệ thống bảo mật cải thiện khả năng nhận diện và ngăn chặn hiệu quả.
Hệ thống thông tin nguồn nhân lực: Các mô hình ML hợp lý hóa việc tuyển dụng bằng cách lọc các ứng dụng và xác định những ứng viên tốt nhất cho một vị trí. Ngoài ra còn có thể dự đoán sự luân chuyển của nhân viên, đề xuất các lộ trình phát triển chuyên môn và tự động hóa lịch trình phỏng vấn. Trí tuệ nhân tạo tạo ra có thể giúp tạo mô tả công việc và tạo tài liệu đào tạo được cá nhân hóa.
Quản lý chuỗi cung ứng: Học máy có thể tối ưu hóa mức tồn kho, hợp lý hóa hậu cần, cải thiện việc lựa chọn nhà cung cấp và chủ động giải quyết tình trạng gián đoạn chuỗi cung ứng. Phân tích dự đoán có thể dự báo nhu cầu chính xác hơn và mô phỏng do AI điều khiển có thể mô hình hóa các kịch bản khác nhau để cải thiện khả năng phục hồi.
Xử lý ngôn ngữ tự nhiên: Các ứng dụng NLP bao gồm phân tích tình cảm, dịch ngôn ngữ và tóm tắt văn bản, trong số những ứng dụng khác. Những tiến bộ trong AI tạo sinh, chẳng hạn như GPT-4 của OpenAI và Gemini của Google, đã cải thiện đáng kể các khả năng này. Các mô hình NLP tạo sinh có thể tạo ra văn bản giống con người, cải thiện trợ lý ảo và cho phép các ứng dụng dựa trên ngôn ngữ phức tạp hơn, bao gồm tạo nội dung và tóm tắt tài liệu.
Tương lai của Machine Learning?
“Tương lai của Machine Learning không chỉ là mô hình mạnh hơn, mà còn là các hệ thống AI có đạo đức, minh bạch và có thể giải thích được." Fei-Fei Li (Nhà tiên phong trong Computer Vision, Giáo sư Stanford)
Machine Learning đang phát triển với tốc độ chưa từng có, được thúc đẩy bởi nghiên cứu sâu rộng từ doanh nghiệp, trường đại học và chính phủ trên toàn cầu. Những đột phá liên tục trong AI và ML khiến các công nghệ hiện tại nhanh chóng lỗi thời, tạo ra một môi trường đổi mới không ngừng. Một điều chắc chắn: ML sẽ tiếp tục là trụ cột trong thế kỷ 21, định hình cách chúng ta làm việc và sinh sống.
Một số xu hướng mới nổi đang định hình tương lai của ML:
Xử lý ngôn ngữ tự nhiên NLP: Các thuật toán NLP đang tiến bộ vượt bậc, giúp AI đàm thoại trở nên tự nhiên và linh hoạt hơn. Các mô hình ngôn ngữ lớn (LLM) như GPT có thể tạo nội dung chuyên sâu, xử lý ngữ cảnh tốt hơn và thích ứng nhanh với nhu cầu kinh doanh. Điều này mở đường cho các chatbot, trợ lý ảo và hệ thống tự động hóa giao tiếp hiệu quả hơn.
Cuộc đua AutoML trong doanh nghiệp: Các ông lớn công nghệ như Amazon, Google, Microsoft, IBM và OpenAI đang cạnh tranh khốc liệt trong việc phát triển nền tảng AutoML. Những dịch vụ này giúp doanh nghiệp dễ dàng ứng dụng ML mà không cần chuyên môn sâu, từ thu thập dữ liệu, chuẩn bị, huấn luyện mô hình đến triển khai. Xu hướng này sẽ giúp ML trở nên phổ biến và dễ tiếp cận hơn bao giờ hết.
ML và XAI có thể diễn giải. Các khái niệm này đang ngày càng được chú ý khi các tổ chức cố gắng làm cho các mô hình ML của họ minh bạch và dễ hiểu hơn. Các kỹ thuật như LIME, SHAP và kiến trúc mô hình có thể diễn giải ngày càng được tích hợp vào quá trình phát triển ML để đảm bảo rằng các hệ thống AI không chỉ chính xác mà còn dễ hiểu và đáng tin cậy.
Học máy đã và đang chứng minh vai trò quan trọng trong việc định hình tương lai của công nghệ và xã hội. Từ trí tuệ nhân tạo, phân tích dữ liệu đến tự động hóa, các thuật toán học máy đang dần thay đổi cách con người tương tác với thế giới.
Hy vọng bài viết của VR360 đã mang đến cho bạn các thông tin bổ ích, giải đáp những thắc mắc xoay quanh Machine Learning.
----
Tài liệu tham khảo:
wikipedia.org/wiki/Machine_learning#Models
techtarget.com/searchenterpriseai/definition/machine-learning-ML
Tin tức mới nhất
Bài viết cùng chủ đề
Bản đồ số địa chỉ đỏ Hà Nội sau 2 năm nhìn lại: Những con số biết nói
 20/07/2026
20/07/2026 
Góc nhìn: Quy chế chuyển đổi số xã phường hiện nay
14/07/2026 
Plane Detection: Công nghệ nhận diện mặt phẳng trong AR
29/06/2026 
LiDAR là gì? Nguyên lý, ứng dụng và vai trò trong số hóa không gian
26/06/2026 
Light Estimation là gì? Ranh giới giữa thực và ảo
15/06/2026 
Cinematic VR là gì? Tương lai của trải nghiệm kể chuyện nhập vai
12/06/2026 
WebXR là gì? Công nghệ nền tảng cho trải nghiệm AR/VR trên trình duyệt web
12/06/2026 
Point Cloud là gì? Công nghệ nền tảng của số hóa không gian 3D
10/06/2026 
Real Time 3D là gì? Ứng dụng & lợi ích cho doanh nghiệp
09/06/2026 Khách hàng tiêu biểu





























































Đăng ký nhận thông tin từ VR360
Địa chỉ Đăng ký Giấy phép Kinh doanh: 63 Phan Đăng Lưu, Phường Hoà Cường Nam, Quận Hải Châu, Thành phố Đà Nẵng, Việt Nam
