Đăng ký nhận báo giá
GRPO là gì? Thuật toán huấn luyện đằng sau DeepSeek


DeepSeek-R1 không chỉ gây ấn tượng bởi khả năng lý luận vượt trội mà còn bởi cách tiếp cận huấn luyện hoàn toàn mới, tập trung vào cơ chế GRPO (Group Relative Policy Optimization). Bài viết này sẽ đi sâu vào lý giải định nghĩa, cơ chế hoạt động của thuật toán GRPO.
GRPO là gì?
Group Relative Policy Optimization (GRPO), tạm dich: Tối ưu hóa chính sách tương đối nhóm, là một thuật toán học tăng cường (Reinforcement Learning - RL) để huấn luyện các mô hình ngôn ngữ lớn (LLM) cho các nhiệm vụ phức tạp như giải toán hoặc viết mã. Được giới thiệu lần đầu trong bài báo DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (https://arxiv.org/abs/2402.03300?ref=ghost.oxen.ai), nhưng cũng được sử dụng trong quá trình huấn luyện sau đó của DeepSeek-R1.
Khác với các thuật toán khác, GRPO tiết kiệm bộ nhớ vì không sử dụng hàm giá trị riêng biệt, thay vào đó, thuật toán này tạo ra nhiều câu trả lời cho mỗi câu hỏi, chấm điểm các câu trả lời bằng mô hình phần thưởng và sử dụng điểm trung bình làm tham chiếu để quyết định kết quả nào tốt hơn.
Ý tưởng cốt lõi của GRPO là từ bỏ mô hình Critic (hàm giá trị) và thay vào đó sử dụng điểm trung bình của một tập hợp các đầu ra cho cùng một vấn đề làm đường cơ sở. Đường cơ sở này có thể được sử dụng để ước tính hàm lợi thế và để tối ưu hóa chính sách. Cách tiếp cận này làm giảm đáng kể độ phức tạp của quá trình đào tạo.
Đối với mỗi vấn đề q, GRPO lấy mẫu một tập hợp các đầu ra {o(1), o(2), …, o(G)} từ chính sách cũ π(θold) rồi tối ưu hóa mô hình chính sách bằng cách tối đa hóa phương trình sau làm hàm mục tiêu.
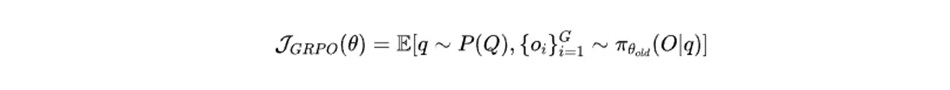

Ý tưởng cốt lõi của GRPO có thể được khai thác mà không cần đến mô hình bên ngoài trong các lĩnh vực như phát triển phần mềm.
Ví dụ:
Mã này có biên dịch được không? Ở đây, chúng ta chỉ cần sử dụng trình biên dịch.
Kết quả của trình kiểm tra cú pháp mã có sạch không? Ở đây chúng ta chỉ cần một trình kiểm tra cú pháp.
Giải thích các thuật ngữ liên quan đến GRPO
Học tăng cường
Học tăng cường (Reinforcement Learning - RL) là một nhánh của học máy, trong đó mô hình học cách đưa ra quyết định thông qua việc tương tác với môi trường, để dần điều chỉnh và đưa ra kết quả tốt nhất. Trong bối cảnh các mô hình ngôn ngữ lớn (LLMs), RL được sử dụng để tinh chỉnh các mô hình này sao cho phù hợp với sở thích của con người và nâng cao hiệu suất của chúng trong các nhiệm vụ cụ thể, chẳng hạn như suy luận toán học hoặc tạo mã.
Tối ưu hóa chính sách
Tối ưu hóa chính sách là một lớp thuật toán học tăng cường (RL) trực tiếp tối ưu hóa chính sách, tức là chiến lược mà tác nhân sử dụng để quyết định hành động dựa trên trạng thái. Một trong những thuật toán tối ưu hóa chính sách phổ biến nhất là Tối ưu hóa Chính sách Gần đúng (Proximal Policy Optimization - PPO),. PPO sử dụng mục tiêu thay thế được cắt xén để ngăn chặn các cập nhật chính sách lớn và dựa vào hàm giá trị để ước tính lợi thế, đảm bảo quá trình huấn luyện ổn định.
Tối ưu hóa chính sách là một nhóm thuật toán trong học tăng cường (RL), tập trung huấn luyện trực tiếp cách ra quyết định của mô hình – tức là chính sách xác định mô hình nên hành động như thế nào trong từng tình huống. Một thuật toán tiêu biểu và được sử dụng rộng rãi là Proximal Policy Optimization (PPO), nổi tiếng về tính ổn định và hiệu quả.
Tuy nhiên, khi các mô hình LLM phát triển lớn hơn và các nhiệm vụ trở nên phức tạp hơn, PPO phải đối mặt với những thách thức, bao gồm chi phí bộ nhớ cao do duy trì hàm giá trị và chi phí tính toán tăng lên. Để khắc phục những hạn chế này, thuật toán GRPO được thiết kế để tăng cường khả năng lý luận của LLM, đặc biệt là đối với các nhiệm vụ toán học và lập trình, bằng cách loại bỏ nhu cầu về hàm giá trị và tận dụng ước tính lợi thế dựa trên nhóm.
GRPO hoạt động như thế nào?
Với mỗi câu hỏi (đầu vào), mô hình sẽ tạo ra nhiều phương án trả lời khác nhau thay vì chỉ một đáp án duy nhất. Tập hợp các phương án này được xem như một nhóm so sánh.
Thay vì đánh giá từng câu trả lời theo một thang điểm cố định, GRPO đánh giá tương quan giữa các câu trả lời trong cùng nhóm. Cụ thể:
- Những phương án có chất lượng tốt hơn mức trung bình của cả nhóm sẽ được ghi nhận là tích cực.
- Những phương án kém hơn mức trung bình sẽ bị đánh giá là chưa đạt.
Điểm mốc so sánh (baseline) trong GRPO chính là giá trị trung bình của nhóm câu trả lời, không phải một mô hình chấm điểm hay giá trị được huấn luyện riêng biệt.
Quá trình này lặp đi lặp lại, giúp mô hình ngày càng tốt hơn theo thời gian. Một chi tiết đáng ngạc nhiên là cách nó sử dụng giá trị trung bình của nhóm làm cơ sở, giúp giảm nhu cầu về bộ nhớ bổ sung trong khi vẫn cải thiện hiệu suất.
Hãy tưởng tượng bạn đang dạy một robot chơi trò chơi đơn giản, trong đó nó phải chọn giữa các con đường khác nhau để đến đích. Robot cần học cách phân biệt con đường nào tốt và con đường nào không tốt.
GRPO hỗ trợ robot thực hiện điều này bằng cách:
Thử các hướng đi khác nhau: Robot thử một vài hướng đi (hành động) khác nhau từ chiến lược (chính sách) hiện tại của nó.
So sánh hiệu suất: Phương pháp này so sánh hiệu quả hoạt động của từng đường dẫn.
Thực hiện những điều chỉnh nhỏ: Dựa trên sự so sánh, robot thực hiện những thay đổi nhỏ trong chiến lược của mình để cải thiện hiệu suất.
Ví dụ: Robot chọn đường đi
Giả sử robot đang ở trong một mê cung và phải chọn giữa ba con đường (A, B và C) để đến đích. Dưới đây là cách GRPO hoạt động từng bước:
Ví dụ về đường dẫn :
Robot sẽ thử từng đường đi một vài lần và ghi lại kết quả.
Đường đi A: Thành công 2 trên 3 lần.
Đường đi B: Thành công 1 trong 3 lần.
Đường đi C: Thành công 3/3 lần.
Như vậy khi bắt đầu trò chơi, robot sẽ tự động được cập nhật và lựa chọn đường đi C.
Tại sao GRPO lại quan trọng?
GRPO tiết kiệm bộ nhớ và tài nguyên tính toán, giúp việc huấn luyện các mô hình lớn trên các thiết bị có hiệu năng hạn chế trở nên dễ dàng hơn. Nó đã được sử dụng trong các mô hình như DeepSeek R1, cạnh tranh với các mô hình AI hàng đầu trong các tác vụ suy luận, cho thấy sự cải thiện đáng kể trong các bài kiểm tra toán học và lập trình.
GRPO mang lại độ ổn định cao hơn so với PPO
PPO (Proximal Policy Optimization) là thuật toán RL phổ biến trong huấn luyện LLM, tuy nhiên khi áp dụng cho các tác vụ suy luận phức tạp, PPO thường gặp vấn đề:
- Reward biến động mạnh giữa các mẫu
- Gradient không ổn định
- Dễ xảy ra hiện tượng mô hình “học lệch” theo tín hiệu thưởng
GRPO khắc phục điểm yếu này bằng cách so sánh tương đối các câu trả lời trong cùng một nhóm, thay vì dựa vào giá trị thưởng tuyệt đối cho từng mẫu đơn lẻ. Nhờ đó Reward có tính “mềm” và ổn định hơn, quá trình tối ưu ít nhiễu hơn. Đây là yếu tố then chốt khi huấn luyện mô hình có chuỗi suy luận dài và nhiều bước trung gian.
Không cần xây dựng reward model phức tạp, GRPO sử dụng chính tập câu trả lời do mô hình sinh ra làm cơ sở so sánh, đánh giá chất lượng theo tương quan trong nhóm, không cần mô hình chấm điểm độc lập.
GRPO đặc biệt hiệu quả với các bài toán suy luận, cho phép mô hình tạo ra nhiều cách giải khác nhau, so sánh và ưu tiên các phương án có lập luận tốt hơn phần còn lại.
Công thức toán học của GRPO
Để hiểu rõ cơ chế hoạt động của GRPO, hãy xem xét công thức sau:
Với mỗi lời nhắc (s_j) , hãy tạo ra (K_j) phản hồi (a_{jk}) , trong đó (k = 1, 2, ..., K_j) .
Mỗi phản hồi (a_{jk}) được chấm điểm bằng mô hình phần thưởng, tạo ra phần thưởng (R_{jk}) .
Tính phần thưởng trung bình cho nhóm: ( (bar{R}_j = frac{1}{K_j} sum_{k=1}^{K_j} R_{jk}) )
Ưu điểm của mỗi câu trả lời là (A_{jk} = R_{jk} - bar{R}_j) , phản ánh mức độ tốt hơn hoặc kém hơn của câu trả lời so với mức trung bình của nhóm.
Việc cập nhật chính sách được hướng dẫn bởi hàm tổn thất sau:
[mathcal{L} = - sum_{j=1}^M sum_{k=1}^{K_j} left( frac{pi_{theta}(a_{jk} | s_j)}{pi_{theta_{text{old}}}(a_{jk} | s_j)} A_{jk} right) + beta sum_{j=1}^M text{KL}(pi_{theta}( cdot | s_j) || pi_{theta_{text{old}}}( cdot | s_j))]
Đây:
(M) là số lượng lời nhắc.
(pi_{theta}) là chính sách mới được tham số hóa bởi (theta) .
(pi_{theta_{text{old}}}) là chính sách cũ.
(beta) là hệ số kiểm soát cường độ của hình phạt phân kỳ KL, đảm bảo chính sách mới không lệch quá xa so với chính sách cũ để duy trì sự ổn định.
Tỷ lệ tầm quan trọng:
[frac{pi_{theta}(a_{jk} | s_j)}{pi_{theta_{text{old}}}(a_{jk} | s_j)}]
Đối với một chuỗi (a_{jk}), giá trị được tính bằng tích của tỷ lệ cho mỗi token trong chuỗi, phản ánh phân bố xác suất của chính sách trên toàn bộ phản hồi.
Các bước triển khai GRPO
Việc triển khai GRPO bao gồm các bước sau:
Chuẩn bị dữ liệu: Thu thập một loạt các câu hỏi, thường ở dạng chuỗi suy luận, dành cho các bài toán lập luận, chẳng hạn như các câu hỏi từ bộ dữ liệu GSM8K và MATH.
Tạo phản hồi: Đối với mỗi câu hỏi, hãy tạo nhiều phản hồi (ví dụ: 64 mẫu cho mỗi câu hỏi, như được sử dụng trong DeepSeekMath) bằng cách sử dụng chính sách hiện tại, với độ dài tối đa là 1024 token.
Chấm điểm thưởng: Sử dụng mô hình thưởng để gán điểm thưởng cho mỗi câu trả lời. Mô hình thưởng, ban đầu được huấn luyện trên một mô hình cơ bản như DeepSeekMath-Base 7B với tốc độ học là 2e-5, đánh giá chất lượng câu trả lời dựa trên độ chính xác và định dạng.
Tính toán lợi thế: Đối với mỗi câu hỏi, hãy tính phần thưởng trung bình (bar{R}_j) của các câu trả lời và tính lợi thế cho mỗi câu trả lời: (A_{jk} = R_{jk} - bar{R}_j)
Cập nhật chính sách: Cập nhật các tham số chính sách để giảm thiểu hàm mất mát, với tốc độ học là 1e-6 cho mô hình chính sách, hệ số KL là 0,04 và kích thước lô là 1024. Thực hiện một lần cập nhật cho mỗi giai đoạn khám phá để đảm bảo tính ổn định.
Quá trình này mang tính lặp đi lặp lại, trong đó GRPO cải thiện mô hình bằng cách tận dụng dữ liệu được tạo ra trong quá trình huấn luyện, biến nó thành một thuật toán học trực tuyến.
So sánh với các phương pháp tối ưu hóa chính sách khác
Để hiểu rõ hơn về GRPO, hãy so sánh nó với các phương pháp khác:

GRPO được xem là một bước tiến đáng chú ý trong học tăng cường dành cho các mô hình ngôn ngữ lớn, khi mang đến một phương pháp huấn luyện tinh gọn hơn, hiệu quả hơn và đặc biệt phù hợp với các bài toán đòi hỏi khả năng suy luận phức tạp. Hy vọng những phân tích trong bài viết đã giúp bạn có cái nhìn rõ ràng và sâu hơn về bản chất, vai trò cũng như tiềm năng ứng dụng của thuật toán GRPO trong các mô hình ngôn ngữ hiện đại.
Nguồn tham khảo:
https://aiengineering.academy/LLM/TheoryBehindFinetuning/GRPO/
https://www.datacamp.com/blog/what-is-grpo-group-relative-policy-optimization
Tin tức mới nhất
Bài viết cùng chủ đề

Plane Detection: Công nghệ nhận diện mặt phẳng trong AR
 29/06/2026
29/06/2026 
LiDAR là gì? Nguyên lý, ứng dụng và vai trò trong số hóa không gian
26/06/2026 
Light Estimation là gì? Ranh giới giữa thực và ảo
15/06/2026 
Cinematic VR là gì? Tương lai của trải nghiệm kể chuyện nhập vai
12/06/2026 
WebXR là gì? Công nghệ nền tảng cho trải nghiệm AR/VR trên trình duyệt web
12/06/2026 
Point Cloud là gì? Công nghệ nền tảng của số hóa không gian 3D
10/06/2026 
Real Time 3D là gì? Ứng dụng & lợi ích cho doanh nghiệp
09/06/2026 
Thuật toán SLAM là gì? SLAM hoạt động như thế nào
02/06/2026 
Case Study: Cách ứng dụng Virtual tour trong công tác tuyển sinh
25/05/2026 Khách hàng tiêu biểu





























































Đăng ký nhận thông tin từ VR360
Địa chỉ Đăng ký Giấy phép Kinh doanh: 63 Phan Đăng Lưu, Phường Hoà Cường Nam, Quận Hải Châu, Thành phố Đà Nẵng, Việt Nam
