Sign up to receive quotes
What is a Neural Network? Working principles, structure and application



Neural Networks are no longer just a distant theoretical concept, now the "brains" behind countless AI applications we interact with every day. With the ability to learn from data without relying on fixed rules, neural networks have become the foundation for many advanced technologies such as image recognition, natural language processing (NLP), speech recognition, and data analysis.
In this article, we’ll explore the basics of neural networks, how they work, and their applications across various fields. Gaining an understanding of neural networks is essential for anyone interested in the advancement of artificial intelligence.
What is a Neural network?
A Neural Network is a machine learning model designed to simulate the way neurons in the human brain transmit signals and process information.
Essentially, a neural network is a mathematical model implemented as an algorithm that enables computers to learn from data, self-adjust, and make increasingly accurate predictions over time.
The system uses interconnected nodes or “neurons”: the input layer receives data from the outside, processes it through one or more hidden layers, and finally the output layer delivers results based on what the network has learned.
This unique structure allows neural networks to adjust their weights to minimize errors and continuously improve their accuracy. That’s why this technology can handle complex problems and is widely applied across various fields such as document summarization, image recognition, and natural language processing (NLP).
History of Neural Networks
The history of neural networks dates back much further than most people might think, possibly even beyond our common assumptions.
The idea of a "thinking machine" is not new; it can be traced all the way back to Ancient Greece. However, it wasn't until the 20th century that a series of breakthroughs laid the groundwork for modern neural networks:
1943: Warren McCulloch and Walter Pitts were the first to model neural activity using mathematical logic, opening the door to a connection between biology and computers.
1958: Frank Rosenblatt introduced the Perceptron, a model capable of “learning” and making decisions based on data. This marked the first step in moving machine learning from theory into practical application.
1974: Paul Werbos developed the backpropagation algorithm, allowing neural networks to improve their accuracy through training iterations. He documented this in his Ph.D. thesis, marking a significant milestone in neural network development.
1989: Yann LeCun applied neural networks to handwriting recognition, demonstrating that AI could process real-world data with remarkable accuracy, a breakthrough that signaled the practical potential of neural networks.
How do Neural networks work?
The working principle of a neural network mainly revolves around two key processes: Forward Propagation and Backpropagation.
So, how exactly does a neural network function? Let’s take a closer look at these two data transmission processes that define how an artificial neural network operates:
Forward Propagation
When data is fed into the network, it flows from the input layer, through one or more hidden layers, and finally reaches the output layer. This flow of data in one direction is known as forward propagation.
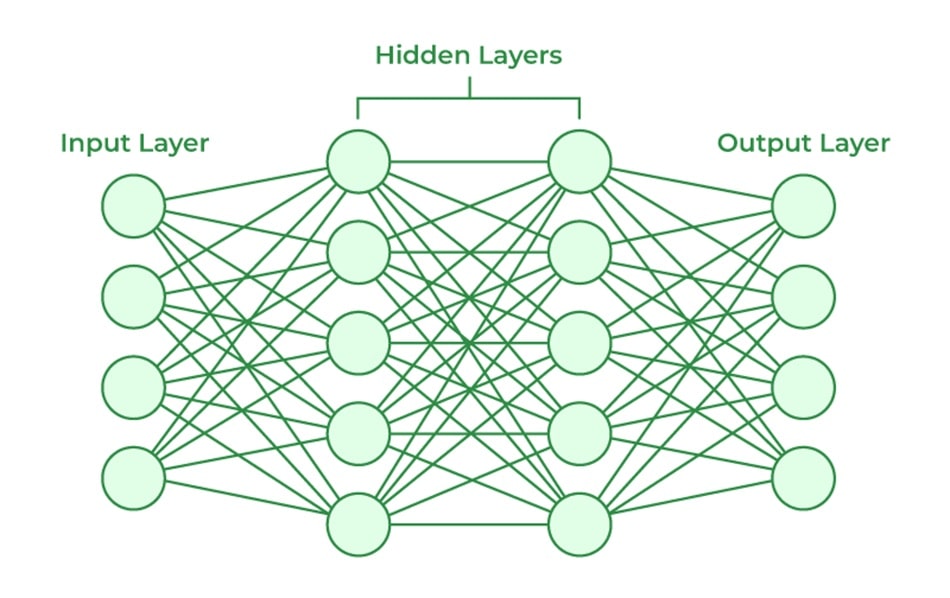
Each neuron in a layer receives inputs from the previous layer, multiplies them by a set of weights, adds a bias, and then applies an activation function to determine its output. This output then becomes the input for the next layer.
The network continues this process until it generates an output prediction.
This forward flow helps the neural network make an initial guess based on the current weights and biases, but this guess is not perfect. That’s where the second process comes in: backpropagation, which corrects the network’s mistakes.
At each neuron, the data is processed through a linear transformation: Each neuron in a layer receives the input, then multiplies these values by the weights of the connections. These values are added together, and a bias is added.
This can be expressed mathematically as follows: z=w1x1+w2x2+…+wnxn+b
Where w is the weight, x is the input, and b is the bias.
Activation function: The result of the linear transformation (denoted by z) is then passed through an activation function. The activation function plays an important role in introducing nonlinearity into the system, helping the neural network learn and recognize more complex patterns. Some common activation functions include ReLU, sigmoid, and tanh.
Backpropagation
If forward propagation is the journey where data "moves forward" to generate predictions, then backpropagation is the reverse journey, where the network steps back to evaluate and determine how to improve.
Immediately after completing forward propagation, the network measures the gap between the prediction and the actual value using a loss function. This is the metric that indicates how well the model "understands" the data.
For regression problems: Mean Squared Error (MSE) is commonly used.
For classification problems: Cross-Entropy Loss is the optimal choice.
The ultimate goal is to make the predicted value progressively closer to the truth.
Gradient Calculation:
The main objective of calculating the gradient is to find the direction in which to adjust the parameters (weights and biases) to reduce the value of the loss function. This process helps improve the model’s prediction accuracy. To do this, the network uses the chain rule in differential calculus to determine how much each weight and bias contributes to the output error.
Weight Update:
Once the gradient is obtained, the network updates all the weights and biases using an optimization algorithm. One of the most popular optimization algorithms is Stochastic Gradient Descent (SGD), a simple yet highly effective learning algorithm.
Weights are adjusted in the opposite direction of the gradient to minimize the loss of function. This adjustment process is performed through parameter update steps, and the size of each step is determined by a parameter called the learning rate.
Iteration:
The entire process - from forward propagation, loss calculation, backpropagation, and weight updates - doesn’t happen just once. It is repeated thousands or even millions of times across the entire dataset.
Each loop (iteration) is a learning step. And with every step, the model becomes more accurate, understands the data better, and delivers smarter responses.
What are the types of Neural networks?
Neural networks can be classified into various types; each designed for specific purposes.
While this is not an exhaustive list, the following are some of the most used types of neural networks that you are likely to encounter in many real-world scenarios:
Feedforward Neural Networks (FNN)
Feedforward neural networks are one of the simplest architectures in artificial neural networks, where data flows in one direction—from input to output—without any loops or cycles.
Multilayer Perceptron (MLP)
The perceptron is one of the earliest neural network models, developed by Frank Rosenblatt in 1958.
A multilayer perceptron consists of an input layer, one or more hidden layers, and an output layer.
These layers use nonlinear activation functions to process data. MLPs are capable of solving more complex tasks, such as classification and prediction in real-world applications.
Convolutional Neural Networks (CNN)
CNNs use convolutional layers to automatically learn hierarchical features from input images.
This process enables the network to efficiently recognize and classify objects in images. CNNs are widely used in:
- Image recognition
- Pattern recognition
- Computer vision
Recurrent Neural Networks (RNN)
RNNs are defined by their feedback loops, allowing them to maintain information across sequences.
They are mainly used for tasks involving time series data or sequential data, such as:
- Stock market prediction
- Sales forecasting
- Natural language processing
Applications of Neural Networks
Neural networks are applied in various fields, such as:
- Medical diagnosis by classifying medical images
- Targeted marketing through filtering social media and analyzing behavioral data
- Financial forecasting by processing historical data of financial instruments
- Energy demand and electrical load prediction
- Process and quality control
- Chemical compound recognition
Below are four key applications of neural networks:
Computer Vision:
This refers to a computer's ability to extract data and deep insights from images and videos. With neural networks, computers can distinguish and recognize images similarly to how humans do. Computer vision is used in various scenarios, such as image recognition systems in self-driving cars, content moderation, facial recognition, etc.
Speech Recognition:
Neural networks can analyze human speech, regardless of voice pattern, pitch, tone, language, or regional accent. Virtual assistants like Amazon Alexa and automatic transcription software use speech recognition to perform tasks such as assisting call center agents, converting conversations, generating subtitles, and more.
Natural Language Processing (NLP):
This is the ability to process natural, human-generated text. Neural networks help computers extract meaningful insights from text data and documents. NLP is used in a variety of cases, such as virtual agents and automated chatbots, document summarization, etc.
Recommendation Engines:
Neural networks can track user activity to provide personalized suggestions. By analyzing user behavior, they can identify new products or services that a specific user may be interested in.
Neural networks are not just a technology—they are a form of “digital brain” that is gradually enabling machines to see, hear, understand, and act like humans.
With the information shared by VR360, we hope this helps you understand what neural networks are, how they work, and how they are applied in real life today.
Latest News
Articles on the same topic
Bản đồ số địa chỉ đỏ Hà Nội sau 2 năm nhìn lại: Những con số biết nói
 20/07/2026
20/07/2026 
Góc nhìn: Quy chế chuyển đổi số xã phường hiện nay
14/07/2026 
Plane Detection: Công nghệ nhận diện mặt phẳng trong AR
29/06/2026 
LiDAR là gì? Nguyên lý, ứng dụng và vai trò trong số hóa không gian
26/06/2026 
What is Light Estimation? The boundary between the Real and the Virtual
15/06/2026 
What Is Cinematic VR? The Future of Immersive Storytelling
12/06/2026 
What Is WebXR? The Foundational Technology Behind Browser-Based AR and VR Experiences
12/06/2026 
What Is a Point Cloud? The foundational technology behind 3D spatial digitization
10/06/2026 
What Is Real-Time 3D? Applications and Benefits for Businesses
09/06/2026 Typical customers





























































Sign up to receive information from VR360
Business License Registration Address: 63 Phan Dang Luu, Hoa Cuong Nam Ward, Hai Chau District, Da Nang City, Vietnam
